
Introduction
MLOps has matured dramatically in 2025, evolving into a must-have discipline for any serious machine learning team. With AI moving from lab to real-world applications, developers now require streamlined pipelines that ensure models can be built, deployed, monitored, and retrained in production environments. This guide offers an actionable blueprint for setting up MLOps pipelines using state-of-the-art tools, best practices, and automation strategies.
Why MLOps Matters More Than Ever in 2025
- Production complexity: ML models are now deployed in real-time systems, mobile apps, IoT, and fintech products.
- Scale & reproducibility: Without MLOps, it’s nearly impossible to reproduce models and keep them updated reliably.
- Compliance & monitoring: Regulatory pressure (e.g., AI Act, CCPA) requires versioning, explainability, and audit trails.
MLOps ensures collaboration, consistency, and confidence from model training to user-facing deployment.
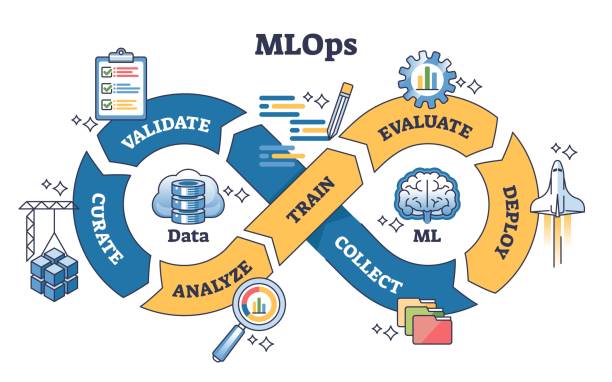
Key Components of a Production MLOps Pipeline
- Data Versioning & Validation
Tools: DVC, Great Expectations, Feast (feature store) - Model Training & Experiment Tracking
Tools: MLflow, Weights & Biases, Optuna - Pipeline Orchestration
Tools: Apache Airflow, Kubeflow Pipelines, Metaflow - Model Packaging & Deployment
Tools: BentoML, TFX, Docker, FastAPI - Monitoring & Feedback Loop
Tools: Prometheus, Grafana, Evidently AI, Seldon Core
Each layer builds toward a scalable and reproducible machine learning lifecycle.
Tool Spotlight: MLflow + BentoML
- MLflow tracks experiments, artifacts, parameters, and metrics across versions.
- BentoML wraps models into Dockerized REST services, deployable to AWS, GCP, or Kubernetes.
- Combined, they streamline deployment with minimal custom infrastructure.
Example: Train with MLflow, then deploy via BentoML CLI with:
bentoml serve my_model:latestCode Snippet: MLflow Tracking Example
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
mlflow.start_run()
model = RandomForestClassifier()
model.fit(X_train, y_train)
mlflow.sklearn.log_model(model, "rf_model")
mlflow.end_run()Best Practices in 2025 for MLOps Pipelines

- Use feature stores to ensure consistency across training and production.
- Automate retraining via CI/CD pipelines (GitHub Actions, GitLab CI).
- Enable drift detection and alerting.
- Containerize inference for portability and scale.
- Schedule batch jobs with Airflow, and real-time pipelines with TFX.
Common Pitfalls to Avoid
- Ignoring data drift and model decay in production
- Poor experiment tracking = unreproducible results
- Deploying models without robust logging or rollback strategies
MLOps in Regulated Environments
- Integrate explainability tools (LIME, SHAP)
- Maintain model cards for transparency
- Log all model decisions & predictions
- Enable user opt-outs and privacy configurations
Conclusion & Call to Action
Building ML systems without MLOps is no longer viable in 2025. Production-ready pipelines must be resilient, transparent, and efficient. By integrating tools like MLflow, TFX, and BentoML, teams can ship high-quality models with confidence.
Explore our other blogs on scalable AI development, DevOps for ML, and ethical model governance.
FAQs
Q: What is the difference between MLOps and DevOps?
MLOps adds ML-specific components like data versioning, model tracking, and drift detection.
Q: Can I use MLflow and TFX together?
Yes. Use MLflow for experiment tracking and TFX for production workflows.
Q: How do I monitor ML models in production?
Use tools like Prometheus, Grafana, and Evidently AI for real-time monitoring.
Q: What’s the best CI/CD setup for MLOps?
GitHub Actions, GitLab CI, and Jenkins integrated with Airflow or Metaflow.
Q: How often should I retrain models in production?
It depends on the application. Use drift detection to automate retraining schedules.